

Introduction
In today’s data-centric world, the vast majority of data is unstructured. This encompasses documents like free-form text, unlabeled images, raw videos, and audio files that don’t conform to a specific data model, making it challenging to extract meaningful information. Businesses need to perform complex processing operations, such as ETL jobs, Map-Reduce transforms, OCR, Computer Vision tools, and various Machine Learning models, to make sense of this data. This requires significant engineering efforts and deep infrastructure knowledge to scale these operations into coherent document processing pipelines.
With Generative AI revolutionizing how businesses integrate and interact with their data, it’s crucial for them to rapidly explore, transform, and enrich their existing data lakes of documents. This needs to be done with the scale, resiliency, and cost-efficiency that the AWS cloud provides.

🚀 Fundamentals
To address these challenges and empower customers to experiment with complex document processing tasks on AWS, we’ve introduced Project Lakechain. This innovative framework, based on the AWS Cloud Development Kit (CDK), allows businesses to express and deploy scalable document processing pipelines using Infrastructure as Code (IaC). Project Lakechain emphasizes modularity and extensibility, offering over 60 ready-to-use components for prototyping complex processing pipelines that scale effortlessly to millions of documents.
Designed to tackle a wide array of use cases, Project Lakechain can handle metadata extraction, document conversion, NLP analysis, text summarization, text translations, audio transcriptions, and more!
🔖 Features
Here are some of the standout features of Project Lakechain:
- 🤖 Composable: A composable API to express document processing pipelines using middlewares.
- ☁️ Scalable: Scales out-of-the-box to process millions of documents and scales to zero automatically when tasks are completed.
- ⚡ Cost Efficient: Utilizes cost-optimized architectures to minimize costs and supports a pay-as-you-go model.
- 🚀 Ready to Use: Offers 60+ built-in middlewares for common document processing tasks, ready to be deployed.
- 🦎 GPU and CPU Support: Supports both GPU and CPU, allowing businesses to balance between performance and cost.
- 📦 Bring Your Own: Allows the creation of custom transform middlewares to process documents and extend Lakechain.
- 📙 Ready-Made Examples: Includes over 50 examples to help businesses quickly start their journey with Lakechain.
With Project Lakechain, Origo continues to provide the best solutions tailored to our client’s needs, leveraging AWS’s advanced capabilities without pushing unnecessary technology. This approach ensures that our clients always receive the most efficient, scalable, and cost-effective solutions available.
Pre-requisites
At Origo, our expertise lies in leveraging the latest developments in AI from industry leaders like Huggingface, Meta, OpenAI, Mistral, and Anthropic. With this in mind, let’s dive into the prerequisites for deploying scalable document processing pipelines using AWS Project Lakechain.
💻 Environment
Project Lakechain has been rigorously tested across various platforms, including different Linux distributions, MacOS, and cloud development environments like AWS Cloud9 and GitHub Codespaces. For an optimal setup, we recommend the following:
- Storage: Ensure your development machine has at least 50GB of free storage to build and deploy all middlewares and examples.
- Dev Container: Utilize our pre-configured Dev Container for GitHub Codespaces to get started quickly. This setup accelerates your development process by providing a ready-made environment.
- 👉 GitHub Codespaces: A cloud-based development environment perfect for Project Lakechain. You can access the official one from AWS at this link.
- Cloud9 Script: Use the official AWS Cloud9 script to resize the EBS storage associated with your Cloud9 instance. This script simplifies the process, ensuring you have enough space for all necessary components.
☁️ AWS Access
To deploy and manage Project Lakechain pipelines, you’ll need access to an AWS account with valid credentials on your development machine. Here’s what you need:
- The AWS documentation describes how to configure the AWS CLI.
- ℹ️ Note: Verify your credentials using the AWS CLI to avoid any hiccups during deployment.
🐳 Docker
Many of Project Lakechain’s middlewares are packaged as Docker containers. Therefore, having Docker installed and running on your development machine is essential. Verify your Docker setup using the Docker CLI to ensure you have access to the Docker daemon.
📦 Node.js + NPM
Node.js and NPM are crucial for installing Lakechain project dependencies. Ensure you have the following setup:
- Node.js 18+: We recommend using Node.js version 18 or higher.
- NPM: The Node.js package manager should be installed alongside Node.js.
- 👉 Tip: Use Node Version Manager (nvm) to easily manage multiple versions of Node.js on your development machine.
🐍 Python and Pip
Python is another key component for Project Lakechain, especially for packaging middlewares written in Python. Ensure you have:
- Python 3.9+: Verify that you have Python 3.9 or higher installed.
- Pip: The Python package installer should be available to manage Python packages.
- 👉 Tip: Use the Python binary to check your Python runtime.
Optional Dependencies
While the following dependencies are optional and will be installed by Project Lakechain using npx, we recommend having them installed on your development machine for a smoother experience:
- TypeScript 5.0+: A superset of JavaScript that compiles to plain JavaScript.
- AWS CDK v2: The AWS Cloud Development Kit (CDK) version 2 for defining cloud infrastructure in code.
By ensuring these prerequisites are met, you’ll be well on your way to deploying robust and scalable document processing pipelines with AWS Project Lakechain. At Origo, we prioritize providing our clients with the most efficient and cutting-edge solutions, and Project Lakechain exemplifies our commitment to excellence.
Architecture
At Origo, we pride ourselves on delivering top-notch solutions for enterprise customers, leveraging the latest advancements in AI, ML, and Generative AI. As AWS partners, we stay ahead of the curve with cutting-edge technologies. In this section, we’ll explore the architecture of AWS Project Lakechain, a revolutionary framework for scalable document processing pipelines.
Below are key components of the infrastructure for Lakechain.
📨 Messaging
The core of Project Lakechain lies in its robust messaging system, which facilitates communication between middlewares. This system, built on AWS SQS (Simple Queue Service) and AWS SNS (Simple Notification Service), models Directed Acyclic Graphs (DAGs) to handle and process documents efficiently.
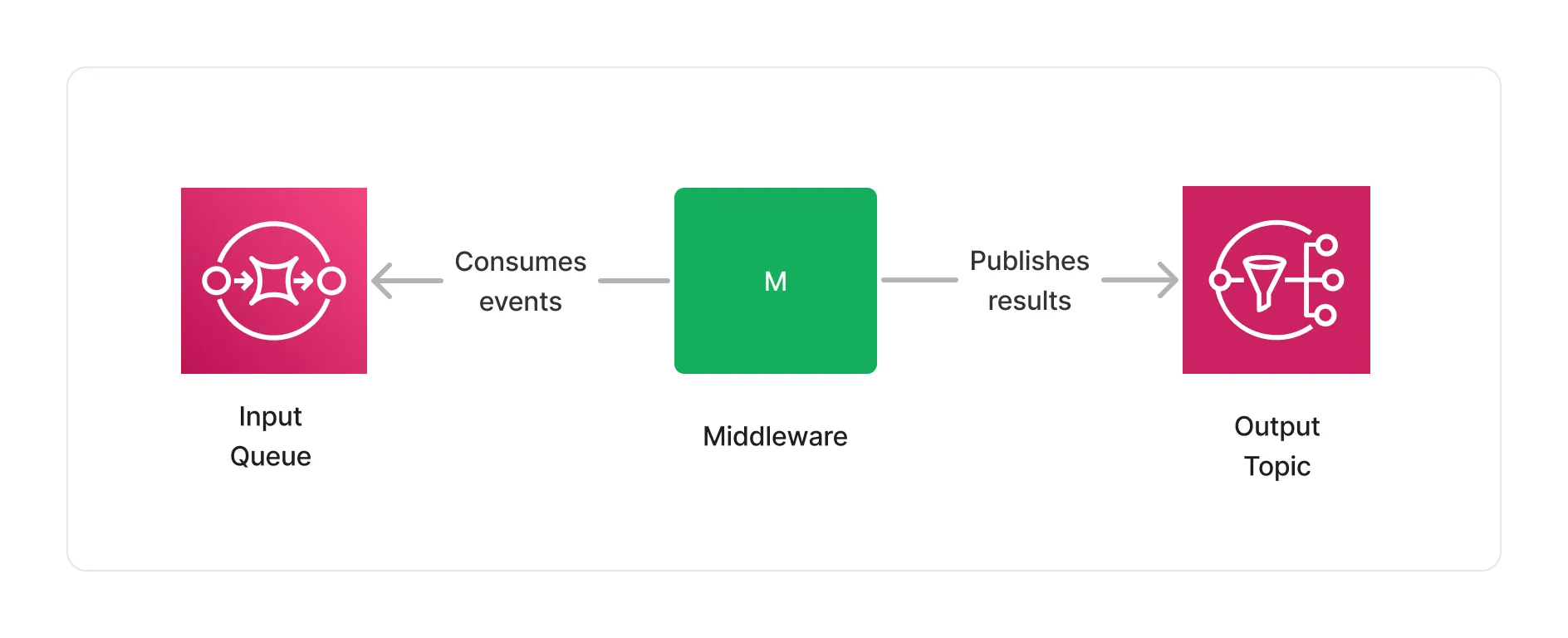
This simple design unlocks many opportunities, that we will explore in the following sections.
Scale
Lakechain leverages the scalability and low-latency features of SQS and SNS. These services support an almost unlimited number of messages, making them ideal for high-throughput workloads.
ℹ️ For instance, during Prime Day 2023, Amazon.com set a new record by processing 86 million messages per second using SQS.
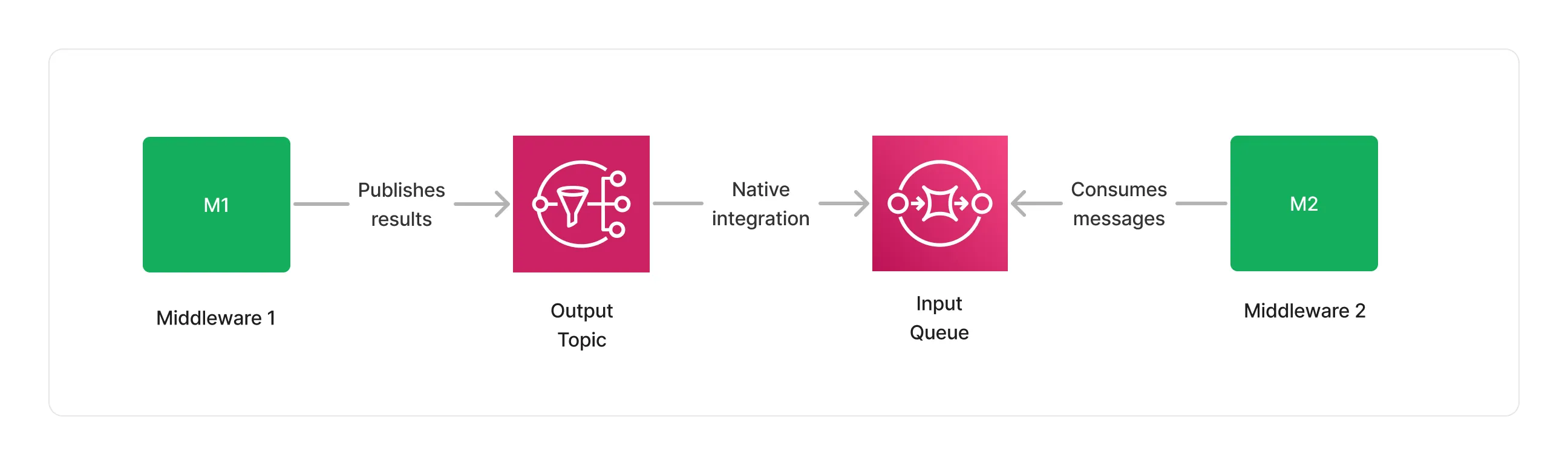
Integration
The seamless integration between SNS and SQS simplifies message delivery, handling retries and throttling automatically. This reduces the need for boilerplate code and leverages tight IAM permissions and integrations with CloudWatch and X-Ray for observability. Moreover, the AWS SDK integration allows various compute options, including Docker containers on ECS, EKS, or Fargate, Lambda functions, and even plain EC2 instances.
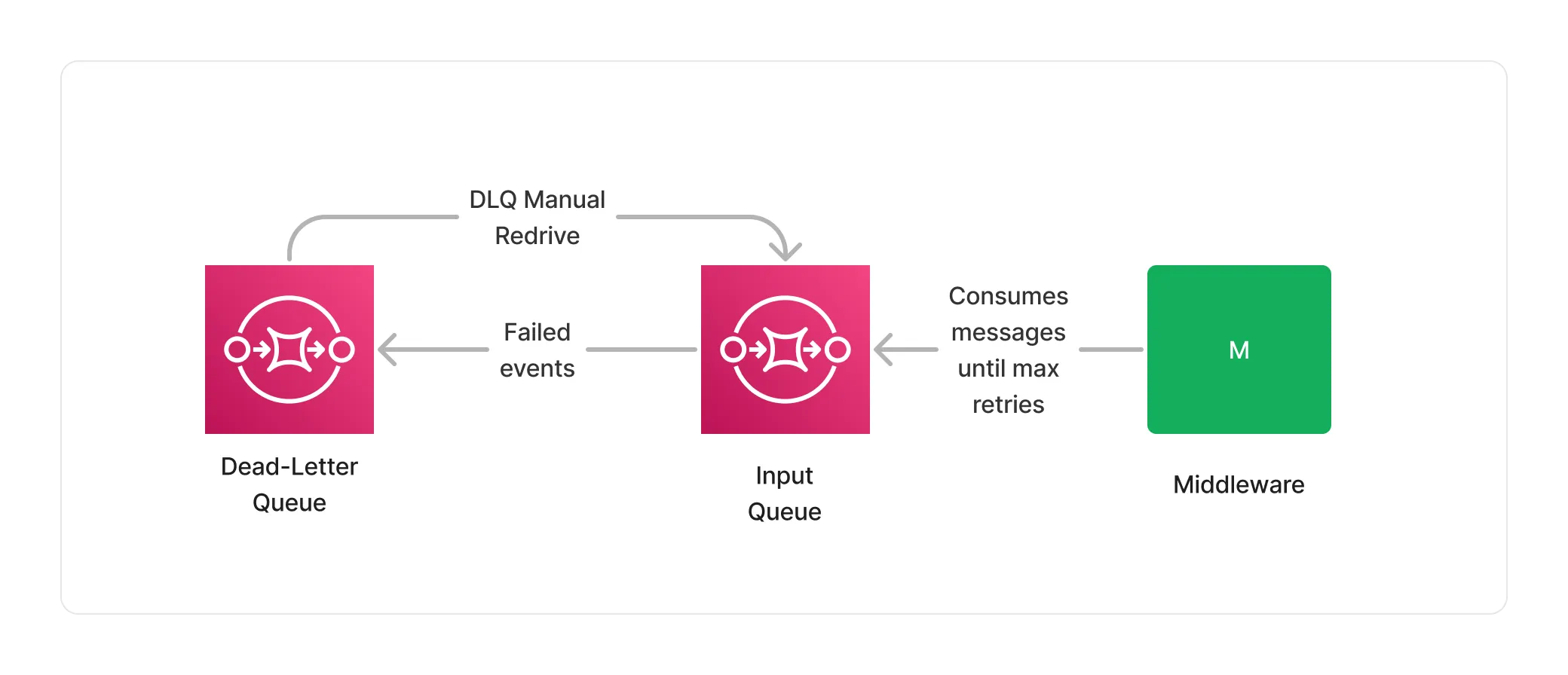
Error Handling
Effective error handling is crucial for document processing. Lakechain uses SQS to automatically retry document processing in case of failure, with configurable retry limits. Events that exceed retry limits are stored in dead-letter queues, which can be monitored and managed to retry failed events.
Throttling
Controlling the rate of document processing is vital to avoid overwhelming downstream services. Lakechain’s pull model allows middlewares to control message consumption rates. For instance, Lambda middlewares can specify maximum concurrency, while other compute types can manually adjust their pull rates.
ℹ️ Lakechain uses a 14-day retention period for SQS queues, providing a buffer for highly throttled workloads.
Batch Processing
Batch processing can enhance efficiency for certain use cases. SQS enables middlewares to consume up to 10 messages simultaneously, and Lambda middlewares can process even larger batches using a Batch Window of up to 5 minutes, handling up to 10,000 messages in a single execution.
Fan-out
For complex DAGs requiring parallel processing or branching, SNS facilitates event fan-out to multiple middlewares. This design supports complex DAG modeling while maintaining integration simplicity and scalability.
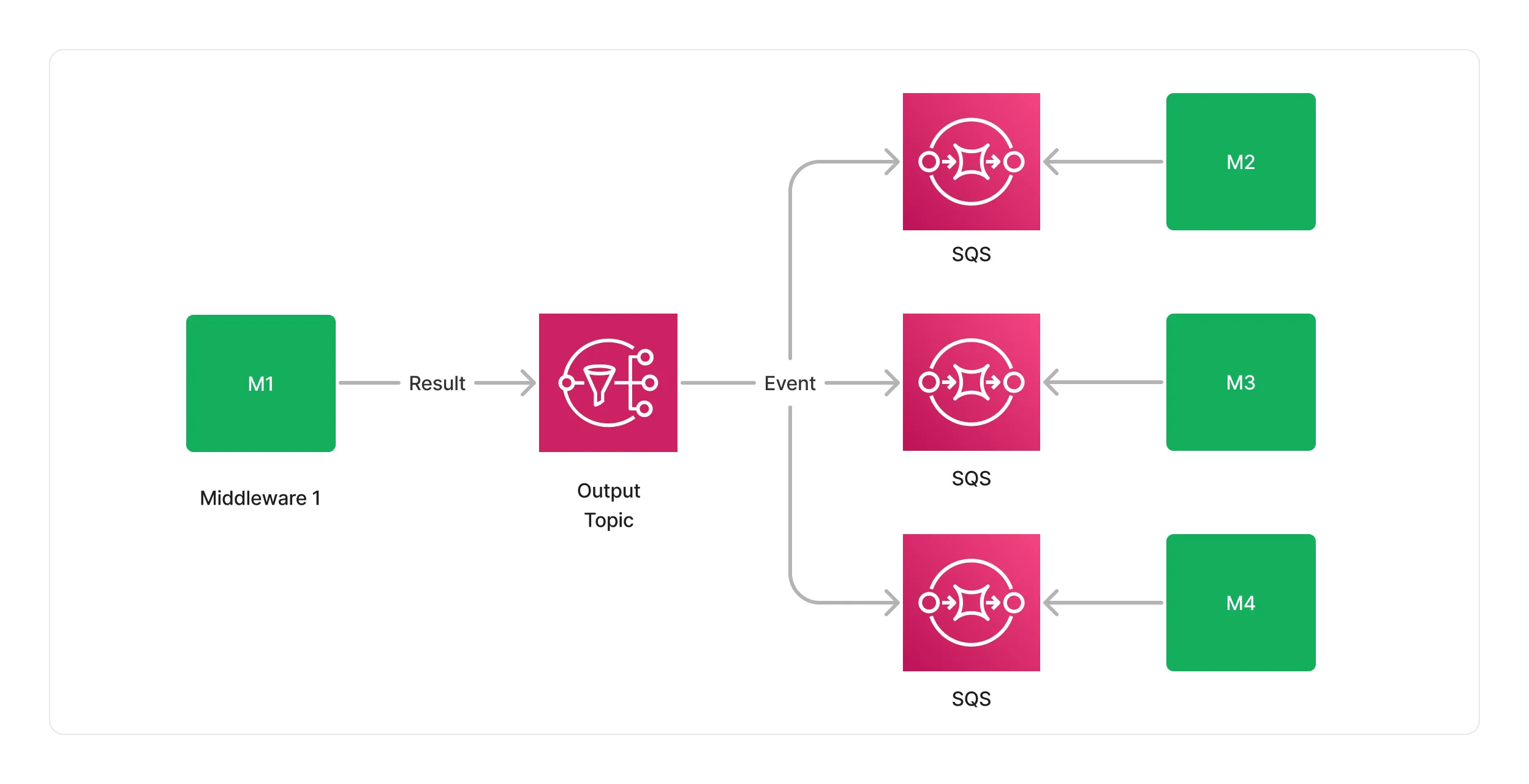
This design makes it possible to model complex DAGs, while keeping the integration between middlewares simple and scalable.
Filtering
Lakechain employs SNS filtering to invoke middlewares based on document type and additional conditions. This ensures that only relevant middlewares are triggered, optimizing processing efficiency.
Cost
This messaging architecture is cost-effective, priced at $0.80 per million messages exchanged between middlewares. This cost includes $0.40 per million SQS SendMessage actions and $0.40 per million SQS ReceiveMessage actions, excluding compute costs.
🗂️ Caching
Each middleware in Project Lakechain gets read access to documents made available by previous middlewares. To ensure accessibility of pointers in document events across all middlewares, Lakechain provides a distributed cache built on S3 (Standard Class). This cache is scalable, low-latency, and cost-efficient, with an S3 Lifecycle Policy that deletes objects after 24 hours to minimize costs.
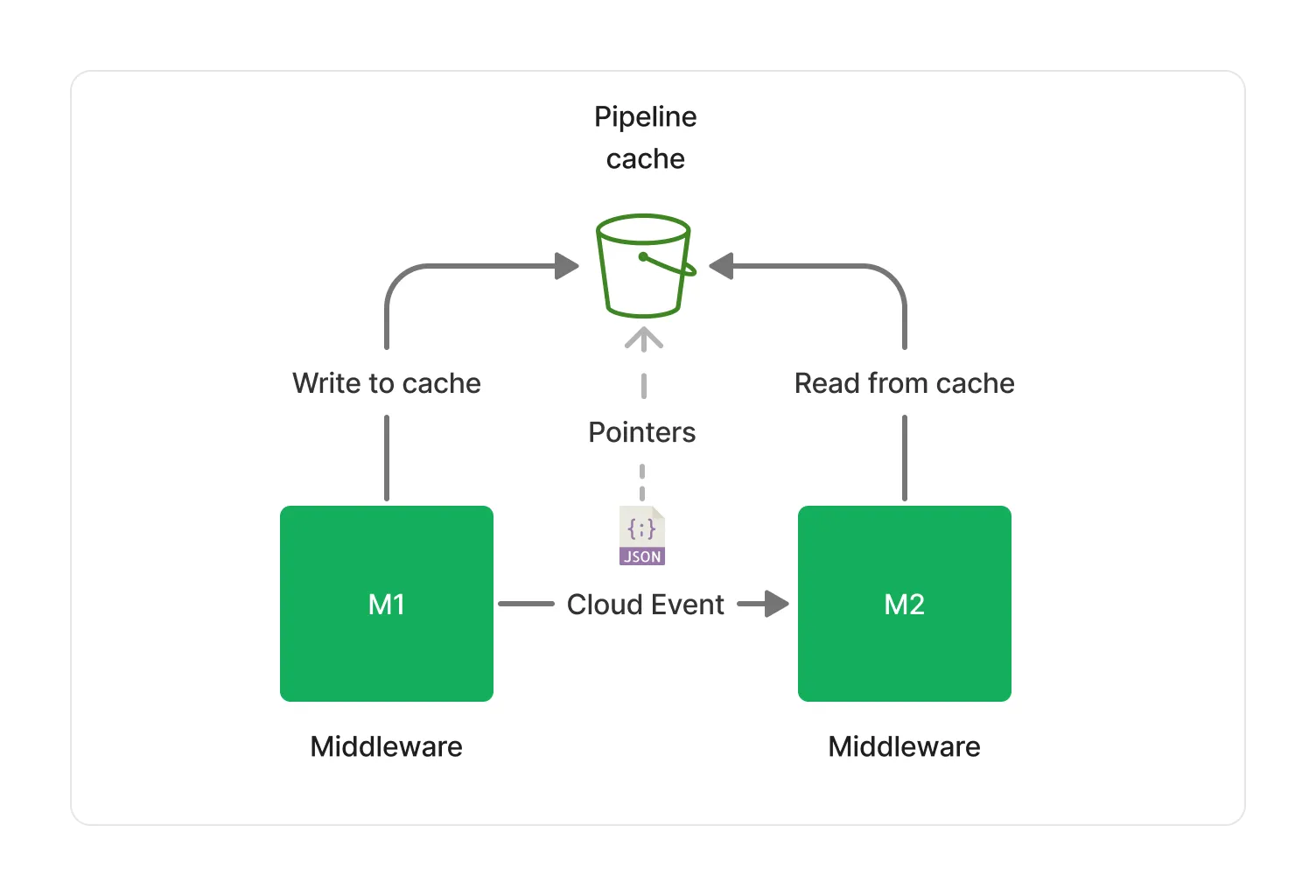
Project Lakechain’s architecture, with its robust messaging and caching mechanisms, provides a scalable, cost-efficient, and highly integrative solution for document processing. At Origo, we leverage this powerful framework to deliver state-of-the-art solutions to our clients, ensuring they stay ahead in the competitive landscape of AI and ML.
Examples
To quickly get started with Project Lakechain and explore the variety of use cases you can implement using it, we’ve created a set of examples that you can deploy in your own AWS account. These examples highlight the power and flexibility of Project Lakechain, demonstrating how it can be tailored to meet diverse business needs. You can access all 50+ examples here.
🎥 Video Summarization Pipeline
First up is the Video Summarization Pipeline. This example showcases how to ingest videos, transcribe their audio tracks into text, and summarize the content while extracting metadata in a structured way using Amazon Bedrock. By leveraging Amazon Transcribe and the Anthropic Claude v3 Sonnet model hosted on Amazon Bedrock, this pipeline can streamline the process of metadata extraction from videos, including video podcasts, TV shows, and daily news, all without your data leaving AWS.

In this pipeline, the transcriptions and extracted metadata are stored in a destination bucket, allowing for easy comparison between the original transcription and the summary. This setup is particularly beneficial for content creators and marketers who need to generate concise, searchable summaries from extensive video content.
🎙️ Building a Generative Podcast
Another fascinating example is the Generative Podcast pipeline. This example demonstrates how to build an intelligent, multi-persona, generative AWS daily news podcast using Project Lakechain. Although it’s not a production-ready application, it highlights the potential of generative AI in content creation.

In this example, Amazon Polly’s long-form synthesis serves as the text-to-speech engine, producing a podcast that discusses AWS releases from March 15, 2024. Thus, by automating the creation of audio content, businesses can efficiently generate high-quality, engaging podcasts to keep their audience informed and entertained.
🤖 RAG Pipeline
Next, let’s explore the Retrieval Augmented Generation (RAG) Pipeline. Consequently, this example showcases how to build an end-to-end RAG pipeline using Project Lakechain and its various middlewares. While it’s only an example and not a production-ready application, it demonstrates the integration of multiple AWS services such as Amazon Transcribe, Amazon Bedrock, and Amazon OpenSearch.

Here’s what this pipeline can do:
- Text Indexing: Convert documents (PDFs, HTML, Markdown, Docx) into text at scale, automatically chunk them, create vector embeddings, and index these embeddings along with the text chunks in an OpenSearch vector index.
- Audio Indexing: Transcribe audio recordings into text and index this text in an OpenSearch vector index.
- Retrieval: Retrieve relevant text chunks from a corpus of documents using semantic search via the RAG CLI.
This setup is ideal for enterprises needing efficient document and audio indexing, making information retrieval seamless and highly accurate.
🎨 Titan Inpainting Pipeline
Finally, we have the Titan Inpainting Pipeline. So, this example leverages Amazon Bedrock and the Amazon Titan image model capabilities to perform image inpainting. But what exactly is image inpainting?

Image inpainting allows you to mask a section of an image and replace it with an AI-generated image. For example, you could mask a house in an image and replace it with a modern house using a specific prompt. This example showcases how to use a mask prompt to achieve this, providing a powerful tool for creative and marketing professionals looking to enhance their visual content.
These examples illustrate the versatility and power of Project Lakechain in transforming document processing workflows. At Origo, we’re excited to bring these capabilities to our clients, leveraging the latest in AI and ML to drive innovation and efficiency.
Conclusion
Project Lakechain represents a significant advancement in scalable document processing, combining the power of AWS services with the flexibility of Infrastructure as Code. Whether you’re summarizing videos, generating podcasts, implementing a RAG pipeline, or performing image inpainting, Project Lakechain offers robust solutions tailored to your needs.
At Origo, we specialize in delivering customized IT consulting services, particularly in the AI, ML, and Generative AI spaces. As an AWS partner, we are well-positioned to help you leverage Project Lakechain’s capabilities to transform your document processing workflows. Our team stays abreast of the latest developments in AI, including open models from Huggingface and Meta, as well as proprietary models from OpenAI, Mistral, and Anthropic.
Ready to take your document processing to the next level? Contact Origo to explore how we can support your initiatives and drive innovation in your organization.
For more information, contact us at info@origo.ec