

In today’s hyper-competitive business landscape, data is the ultimate differentiator. But simply having data isn’t enough. To truly gain an edge, you need to unlock the hidden insights within, turning raw information into actionable intelligence. That’s where Retrieval Augmented Generation (RAG) comes in and Amazon Bedrock offers a great alternative to build a solution.
Imagine asking your data complex business questions in plain English—questions about customer trends, market dynamics, and even operational bottlenecks—and receiving accurate, synthesized answers in real-time. No more sifting through spreadsheets or running complex queries. With RAG, your data becomes a powerful, interactive knowledge base.
This blog post guides you through building a robust, end-to-end RAG solution using Amazon Bedrock’s cutting-edge technology and the streamlined deployment capabilities of the AWS Cloud Development Kit (AWS CDK). We’ll even provide a link to our GitHub repository, so you can get started right away.
Why RAG Matters for Your Business

RAG represents a paradigm shift in business intelligence, bridging the gap between powerful AI models and your organization’s unique data. Here’s how it translates into tangible business benefits:
- Accelerated Decision Making: Empower your teams across all departments with on-demand access to critical insights, enabling faster, more informed decision-making.
- Enhanced Operational Efficiency: Automate answers to complex business questions, freeing up valuable employee time and resources to focus on strategic initiatives.
- Uncover Hidden Opportunities: Gain deeper, more nuanced insights into your market, your customers, and your own operations, revealing hidden opportunities for growth and innovation.
- Gain a Competitive Edge: In the race for data-driven dominance, RAG provides a significant advantage, allowing you to extract maximum value from your information and outperform the competition.
Build Your Own RAG Solution: A Step-by-Step Guide
Step 1: Gather Your Tools
- AWS Account: You’ll need an active AWS account to access the necessary services, and familiarity with FMs, Amazon Bedrock, and Amazon OpenSearch Service.
- Amazon Bedrock: This fully managed service provides access to powerful Foundation Models (FMs), including those ideal for RAG like Amazon Titan Embeddings V2.

- AWS CDK: The AWS CDK enables infrastructure-as-code, streamlining the deployment and management of your RAG solution. For installation instructions, refer to the AWS CDK workshop.
- Data Source: Have your business documents ready in an Amazon S3 bucket. Supported formats include .txt, .md, .html, .doc/docx, .csv, .xls/.xlsx, and .pdf
Step 2: Prepare Your Environment
Clone the Repository: Get started by cloning our GitHub repository containing the solution’s code:
git clone https://github.com/aws-samples/amazon-bedrock-samples.gitNavigate to the Solution Directory:
cd knowledge-bases/ features-examples/04-infrastructure/e2e_rag_using_bedrock_kb_cdkCreate a Virtual Environment:
$ python3 -m venv .venv
$ source .venv/bin/activateInstall Dependencies
$ pip install -r requirements.txtStep 3: Configure and Deploy
AWS Credentials: Export your AWS credentials, ensuring the associated role has the necessary permissions for CDK deployments:
export AWS_REGION=”<region>” # Same region as ACCOUNT_REGION above
export AWS_ACCESS_KEY_ID=”<access-key>” # Set to the access key of your role/user
export AWS_SECRET_ACCESS_KEY=”<secret-key>” # Set to the secret key of your role/userPrepare for Deployment:
./prepare.shBootstrap CDK (If Necessary): If this is your first time deploying with CDK, run:
cdk bootstrapSynthesize CloudFormation Templates:
$ cdk synthDeploy Your Stacks: Deploy the stacks in the following order:
$ cdk deploy KbRoleStack
$ cdk deploy OpenSearchServerlessInfraStack
$ cdk deploy KbInfraStackOnce deployment is finished, you can see these deployed stacks by visiting the AWS CloudFormation console as shown below. Also, you can note knowledge base details (i.e. name, id) under the resources tab.

Step 4: Ingest Your Data & Begin Querying
Access Knowledge Bases: Navigate to the Amazon Bedrock console and select “Knowledge bases.”
Initiate Data Ingestion: Choose your newly created knowledge base and select “Sync” to initiate data ingestion from your S3 bucket.
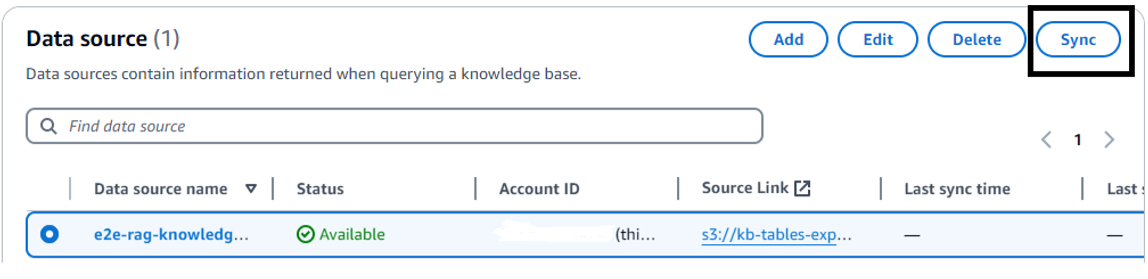
Select Your Foundation Model: Choose your preferred FM for retrieval and generation (ensure model access has been granted within Amazon Bedrock).
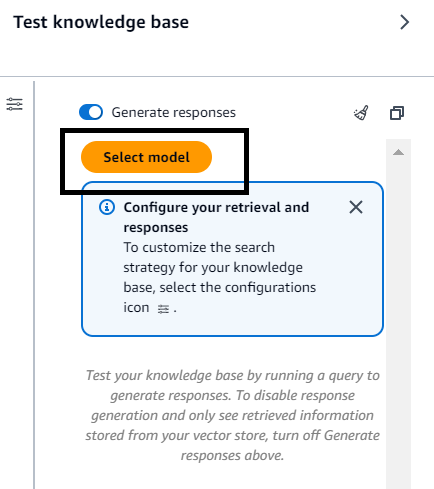
Start Asking Questions! Once data ingestion is complete, you can start querying your data using natural language.
Step 5: Clean Up Resources (Optional)
To avoid incurring unnecessary charges, delete the provisioned S3 bucket files and the CloudFormation stacks when no longer needed.
To delete the CloudFormation stacks:
cdk destroy --allOrigo: Your Partner in Data-Driven Transformation

Building a powerful RAG solution is within your reach, and the benefits are undeniable. By harnessing the combined power of Amazon Bedrock and the AWS CDK, you can unlock hidden insights within your data, drive smarter decision-making, and accelerate innovation across your organization.
Origo specializes in empowering businesses like yours to navigate the complex world of data and AI. Our team of experts provides tailored solutions, guiding you through every step of your data transformation journey, from initial strategy to deployment and beyond.
Contact us today to explore how Origo can help you harness the full potential of your data with cutting-edge solutions like RAG.
For more information, contact us at info@origo.ec.