

Introduction
In the evolving landscape of AI and machine learning, privacy and data security have become paramount, especially in enterprise applications. ChatGPT, while revolutionary, has raised questions about data usage and privacy. Addressing these concerns, this blog post explores a compelling alternative: creating a Retrieval-Augmented Generation (RAG) model using open-source large language models (LLMs) and Amazon Web Services (AWS) tools. This approach not only offers a viable ChatGPT alternative but also ensures enhanced control over data privacy and security, making it ideal for enterprises concerned about how their data is used. We will guide you through setting up a RAG model in Amazon SageMaker, ensuring optimal use of your enterprise data without compromising on privacy.
In this detailed walkthrough, we’ll cover everything from the basics of RAG models, and their advantages in terms of data privacy, to a step-by-step implementation guide using AWS tools. Whether you’re looking to build a ChatGPT alternative that leverages your enterprise data securely, or simply curious about the intersection of AI and data privacy, this post will provide valuable insights and practical steps.
Understanding Retrieval-Augmented Generation Models: A ChatGPT Alternative with Enhanced Privacy
In the quest for effective alternatives to ChatGPT, especially in contexts sensitive to privacy and data security, open-source models have emerged as a beacon of potential. These models offer numerous advantages, particularly in terms of cost, as they are generally lighter and more adaptable compared to their proprietary counterparts.
Open-Source Models: A Cost-Effective and Flexible Solution
Open-source language models, available on platforms like Hugging Face, provide a cost-effective solution for businesses and developers. Their “lighter” nature, in terms of computational requirements, makes them accessible to a wider range of users, including small to medium-sized enterprises. This accessibility democratizes the use of advanced AI technologies.
Finding the Right Model: Hugging Face Resources
Hugging Face, a prominent hub for AI and machine learning models, offers a wealth of resources for those seeking open-source alternatives. Two key resources are the Open LLM Leaderboard and the LLM Embedding Leaderboard. These leaderboards provide a comprehensive overview of various models, ranked and evaluated based on different criteria, making it easier for users to select a model that best fits their specific needs.
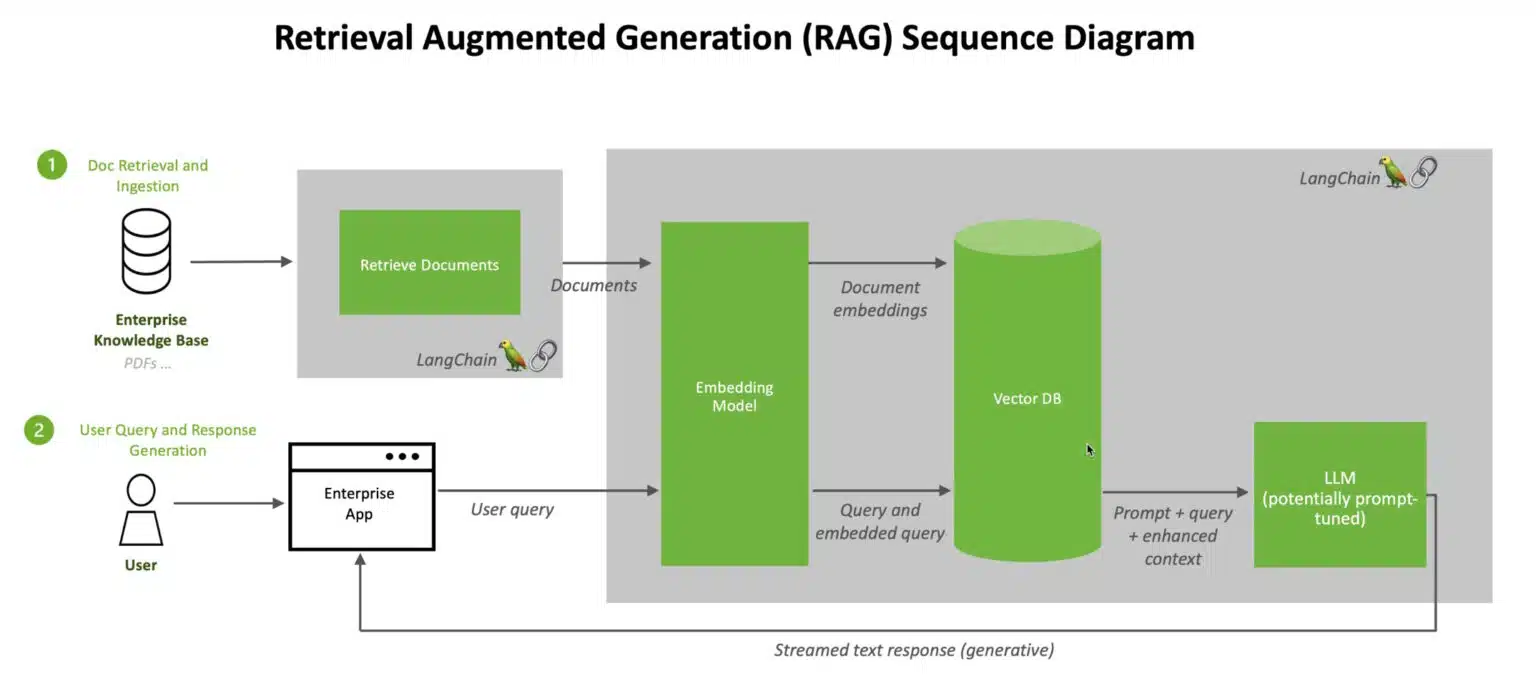
What is a Retrieval-Augmented Generation Model?

Moving deeper into the realm of privacy-conscious AI solutions, we encounter Retrieval-Augmented Generation (RAG) models. A RAG model is a sophisticated AI tool that amalgamates the capabilities of a large language model with an information retrieval system. Unlike traditional models, which generate responses based solely on their training, RAG models actively pull in external information to augment their output. This approach significantly enhances the relevance and accuracy of the responses.
RAG Models: Addressing Privacy Concerns in AI
One of the paramount concerns with models like ChatGPT is the question, “Is ChatGPT using my data?” RAG models, particularly when built on open-source foundations and implemented in controlled environments like AWS, offer a reassuring answer. By enabling more control over the data retrieval sources, RAG models can be tailored to use enterprise-specific databases or securely curated datasets. This ensures that the generated content is not only accurate and contextually relevant but also respects the privacy and confidentiality of enterprise data.
RAG models represent an innovative step forward in addressing the concerns surrounding ChatGPT alternatives, particularly in terms of data privacy. They offer a harmonious balance between advanced AI capabilities and the ethical use of data, making them an attractive option for enterprises looking to leverage AI while maintaining strict control over their data.
Exploring the Tools for Building a RAG Chatbot: From LangChain to Mistral LLM
In building our Retrieval-Augmented Generation (RAG) model, we’ll be utilizing a suite of powerful tools, each contributing uniquely to the development of a privacy-focused ChatGPT alternative. Let’s delve into these tools and understand their roles in our project.
LangChain: Streamlining LLM Integration
LangChain is a toolkit designed to transition Large Language Model (LLM) applications from prototype to production seamlessly. It offers flexible abstractions and an AI-first toolkit, ideal for building context-aware applications that require reasoning capabilities. LangChain simplifies the process of integrating and managing LLMs, ensuring that our chatbot can effectively understand and respond to complex queries.
FAISS by Facebook: Enhancing Similarity Search
FAISS, developed primarily at Meta’s Fundamental AI Research group, is a C++ library with Python/numpy wrappers. It’s designed for efficient similarity search and clustering of dense vectors, making it a crucial component in our RAG model. FAISS can handle vector sets of any size, including those not fitting in RAM, and some of its most practical algorithms are GPU-implemented. This tool will power the retrieval part of our RAG model, ensuring quick and accurate information fetching.
FlagEmbedding: Streamlining Text to Vector Mapping
FlagEmbedding is a remarkable tool for mapping text to low-dimensional dense vectors. These vectors are versatile, suitable for retrieval, classification, clustering, or semantic search tasks. FlagEmbedding’s capability to work in vector databases for LLMs makes it an ideal choice for our embedding needs, ensuring that our RAG model can efficiently process and understand the text data.
Mistral-7B-Instruct-v0.1: The Core LLM
The Mistral-7B-Instruct-v0.1 model is a fine-tuned version of the Mistral-7B generative text model. It’s tailored for conversational contexts, having been trained on various publicly available conversation datasets. This model will serve as the backbone of our chatbot, providing robust and contextually relevant text generation capabilities.
Amazon SageMaker: The Development Environment
Our project leverages Amazon SageMaker’s Jupyter Notebook instance for development and implementation. SageMaker’s managed environment simplifies the process of model training, testing, and deployment. For those interested in the complete code and detailed implementation steps, it’s available on our GitHub page.
By combining these tools—LangChain for LLM management, FAISS for efficient data retrieval, FlagEmbedding for text processing, and Mistral-7B-Instruct-v0.1 as our core LLM—alongside the robust environment of Amazon SageMaker, we’re set to build a RAG model that’s not only a viable alternative to ChatGPT but also one that places a premium on privacy and data security. In our next section, we’ll delve into setting up and utilizing these tools within the SageMaker environment.
Setting Up Your Amazon SageMaker Notebook: A Step-by-Step Guide for a Privacy-Centric ChatGPT Alternative
Creating an Amazon SageMaker notebook is a pivotal step in developing a Retrieval-Augmented Generation (RAG) model, particularly for those seeking a ChatGPT alternative that emphasizes privacy and secure data usage. Let’s walk through the process:
Accessing Amazon SageMaker
Start by navigating to the AWS Console. Search for Amazon SageMaker, a robust and user-friendly platform ideal for building, training, and deploying machine learning models.

Creating a New Notebook Instance
In the SageMaker dashboard, locate the ‘Notebook’ menu on the left. Here, we’ll create a new notebook instance. We’re opting for a straightforward deployment, avoiding more complex options like JumpStart or SageMaker Studio, to keep the process accessible.

Selecting the Instance Type
For this demonstration, we’ll use a standard instance type. The ml.t3.medium with Amazon Linux is an excellent choice for balancing performance and cost. Remember, the larger the instance, the faster the computing capabilities, which can be crucial when working with large datasets or complex models.

Setting Up the IAM Role
This is an important step: Ensuring the right permissions is critical. Your notebook instance needs an IAM (Identity and Access Management) role with necessary permissions. In our setup, we require permissions for both Amazon S3 and Amazon Textract. You can either create a new role or modify an existing one. For simplicity, we’re using the pre-configured AmazonSageMaker-ExecutionRole and adding Textract access. This step underscores our commitment to ‘ChatGPT privacy’, ensuring that the model only accesses necessary and authorized data, addressing concerns like “Is ChatGPT using my data?”

Launching and Interacting with the Notebook
Once the notebook instance is ready, open it and begin interacting. For those who want to follow along with our specific project, the Jupyter notebook is available on GitHub. This notebook will guide you through implementing a RAG model, leveraging tools like LangChain and FAISS, and utilizing the Mistral-7B-Instruct-v0.1 LLM for generating responses.

Setting up a notebook in Amazon SageMaker is a straightforward yet crucial part of building a RAG model. This process not only facilitates the development of a ChatGPT alternative but also ensures that ‘using enterprise data with ChatGPT’ is done in a secure, controlled, and privacy-conscious manner. In the next section, we’ll delve into the specifics of implementing the RAG model within this notebook environment.
Deep Dive into the RAG Chatbot Notebook: Crafting a ChatGPT Alternative with Enhanced Privacy and Flexibility
In our final section, we’ll delve deeper into the specifics of the Jupyter Notebook, highlighting its key features and functionalities. This comprehensive guide illustrates how we’ve addressed critical aspects of building a privacy-focused ChatGPT alternative, emphasizing adaptability and security.

Handling PDF Documents with AWS S3 and Textract
The notebook demonstrates how to load PDF documents into an Amazon S3 bucket and extract information using Amazon Textract. This feature is particularly useful as it allows users to experiment with various PDFs, tailoring the chatbot’s knowledge base to specific needs or industries.
Evaluating the LLM’s Initial Performance
An insightful part of the notebook involves an initial retrieval of information without the context of the PDF documents. This allows users to observe the baseline performance of the Mistral LLM, which, in the absence of context, may not provide highly accurate answers. This step underscores the importance of context in enhancing the effectiveness of LLMs.
Transforming PDF Content for Efficient Retrieval
A critical section of the notebook outlines the process of transforming the extracted information from PDFs into logical chunks. These chunks are then loaded into Facebook’s FAISS, an efficient library for similarity search and clustering of dense vectors. This process is key to enabling the RAG model to search and retrieve relevant information quickly and accurately.
Improved Retrieval with Contextualized Documents
The notebook further showcases how the retrieval process improves significantly once the PDF documents are integrated as part of the context. The LLM’s responses become more accurate and contextually relevant, demonstrating a clear understanding of the concepts related to the provided information.
Security, Instance Selection, and Engineering Considerations
Addressing concerns around “ChatGPT privacy” and “using enterprise data with ChatGPT,” the notebook includes essential considerations related to security for accessing the solution. It guides users in choosing the appropriate type of instance for deployment, and delves into data ingestion and prompt engineering strategies. These elements are crucial for refining the solution’s performance and ensuring its suitability for various business applications.

Conclusion
As we wrap up our exploration of creating a Retrieval-Augmented Generation (RAG) model as a ChatGPT alternative, it’s clear that the journey toward innovative AI solutions is both exciting and complex. This endeavor goes beyond just technology; it’s about forging a path that respects privacy, harnesses data responsibly, and aligns with specific business needs.
In this context, Origo stands as a crucial partner for businesses venturing into the world of AI. Our expertise in data engineering and ingestion, coupled with our ability to tailor Open Source Large Language Models to specific requirements, positions us uniquely to help businesses navigate these waters. Moreover, our focus on prompt engineering ensures that the responses generated by these models are not only accurate but also contextually relevant and aligned with your business objectives.
We invite you to collaborate with Origo as you embark on this journey. Whether it’s refining data processes, selecting the right AI models, or optimizing interactions for the best outcomes, we’re here to guide and assist. Together, we can unlock the true potential of AI in a way that’s ethical, efficient, and perfectly suited to your business needs.
Join us at Origo, and let’s shape the future of AI together.
For more information, contact us at info@origo.ec.
Disclaimer:
Please note that the original author of the Jupyter Notebook discussed in this blog post is Julien Simon, who is affiliated with Hugging Face. This Notebook and its methodologies were extensively referred to in his YouTube video, which can be viewed here. The video serves as an excellent resource for those interested in delving deeper into the creation of RAG models for Open Source Large Language Models. The contents of this blog post are based on the insights and framework provided by Julien Simon’s work, adapted and expanded upon for the specific context of building a ChatGPT alternative with a focus on privacy and enterprise data utilization.